Scale your org's GitHub runners in Azure Container Apps

This is the second post of the series about hosting your GitHub org’s self-hosted runners in Azure Container Apps. The first episode covers the essentials of the solution, concluding with a testing workflow running in an Azure Container App.
This post will focus on scaling the self-hosted runners, combining two features of Azure Container Apps: jobs and the builtin KEDA integration.
In the previous episode…
If you haven’t read my previous post you can check out this section that presents the solution used in this series.
There is also a GitHub repository with all the code and instructions on how to deploy it in your environment.
The KEDA GitHub runner scaler
KEDA is the de-facto autoscaler of the Kubernetes ecosystem. It can sale workloads in a cluster based on event-driven sources called scalers. Among the many available scalers there is the GitHub Runner Scaler, and like any KEDA scaler, we can use it to scale our Container App.
It works by querying the GitHub REST API to get the number of queued jobs, and will add or remove replicas to the Container App accordingly. This means we need to configure how the scaler will authenticate against the GitHub REST API, and which filters to count the jobs that are worth a scale.
Choosing the right version of the scaler
The link to the KEDA documentation in the previous paragraph leads to the latest version of KEDA (2.12 at the time of writing this post). Before browsing the docs I strongly advise you to check the KEDA version used by your Container Apps Environment: 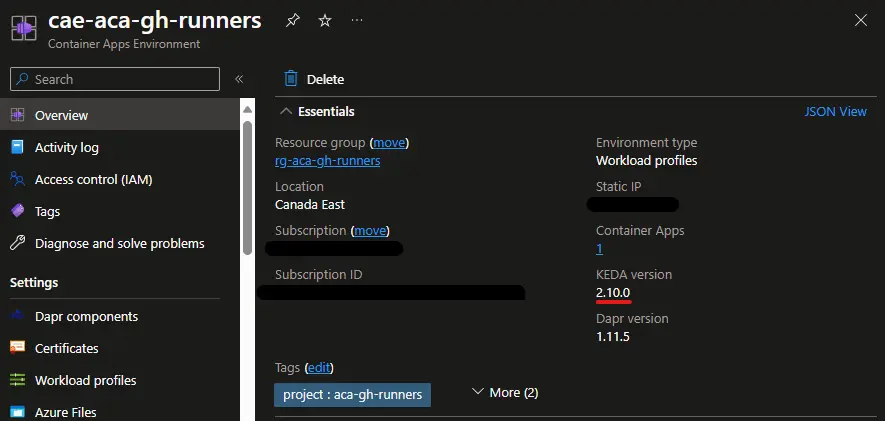 Looks like I don’t have the latest version 🥹
Looks like I don’t have the latest version 🥹
Azure Container Apps is a managed service where you don’t manage the KEDA version used by the underneath cluster. Using Azure Kubernetes Service will probably give you more control on this, but with Container Apps the updates are rolled by service.
Before I understood this, I was trying to use the scaler’s authentication with a GitHub App private key, which is not available in the KEDA version used by my Container App Environment.
About ephemeral runners
GitHub recommends the use of ephemeral runners for autoscaling. It means that each runner processes a single job, and each job is processed by a fresh runner. This makes job execution more predictable and prevent the risk of using a compromised runner or exposing sensitive information.
The use of ephemeral runners depends on the container image we use. The image used in the previous post requires the EPHEMERAL environment variable set to 1. At the end it’s just a flag passed to a script when the runner is initialized.
Container Apps Jobs
In the previous post a Container App has been set-up a single self-hosted runner. The App was always running, regularly polling the GitHub REST API for jobs to run, and the same runner was processing all the jobs.
At first I wanted to add a scaling rule on top of that but after some research there is a better approach by using Azure Container Apps Jobs.
Jobs are designed for containerized tasks with a finite duration just like our ephemeral runners.
They also support event triggers from KEDA scalers so it’s definitively a good fit for this scenario.
This page in the docs might help if you’re hesitating between apps or jobs for another scenario.
Before jumping into the code, this little diagram shows what will happen once the runners will scale out: 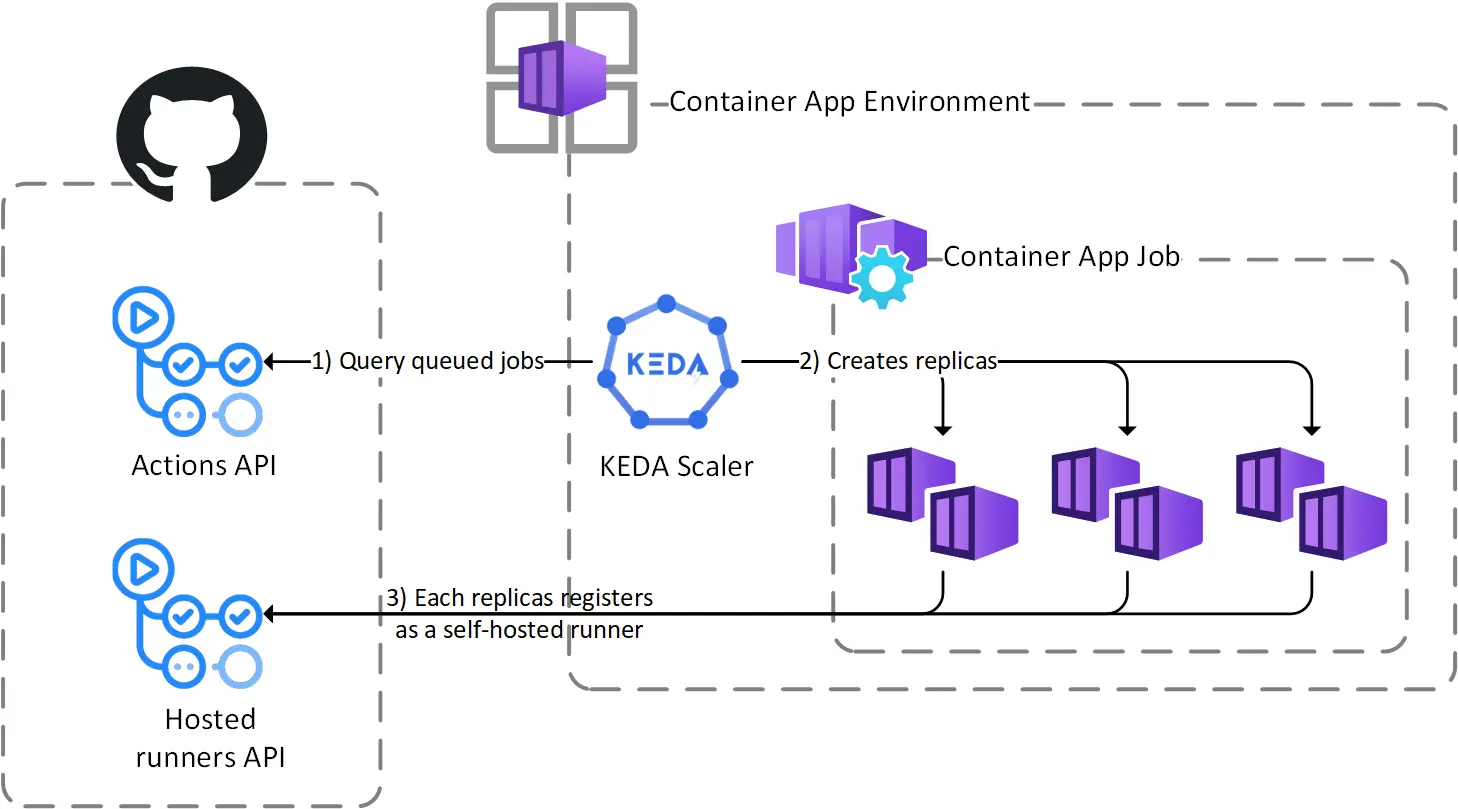 It also shows the changes from the diagram of the previous post
It also shows the changes from the diagram of the previous post
Update the Bicep code
Turning the Container App into a job
To use a Container App Job, we need to use the Microsoft.App/jobs resource type instead of Microsoft.App/containerApps. This change is easy as both resource types share a lot of common properties:
- The
registriesandsecretsdeclaration are the same - The
template/containersarray is also the same for both resources
There is a slight difference on the property that links to the Container App Environment (environmentId vs managedEnvironmentId), and the scaling part is also different so let’s focus on that.
Configuring the scaler
This is the most important part, it consists in matching the trigger specification from the scaler’s docs with a rule in the eventTriggerConfig object of the resource:
- the
metadataobject contains the parameters of the scaler: the scope, organization, labels, etc. - the
autharray tells how the scaler authenticates against the GitHub REST API: using a secret reference to a PAT in our case as the GitHub App private key is not supported in our version of KEDA.
This code snippet highlights the required changes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
resource acaJob 'Microsoft.App/jobs@2023-05-01' = {
// ...
properties: {
environmentId: acaEnv.id
configuration: {
// ...
replicaTimeout: 1800
triggerType: 'Event'
eventTriggerConfig: {
scale: {
rules: [
{
name: 'github-runner-scaling-rule'
type: 'github-runner'
auth: [
{
triggerParameter: 'personalAccessToken'
secretRef: 'github-access-token'
}
]
metadata: {
owner: gitHubOrganization
runnerScope: 'org'
}
}
]
}
}
}
// ...
}
The whole code is available in the GitHub repo, by default the Container App Job module is selected, you can still check/compare with the Container App module.
Testing the runner at scale
Once a deployment has been made with the new version of the Bicep code, no runner should be visible at first in GitHub. But if we manually trigger the Test self-hosted runners workflow several times, we should see this: 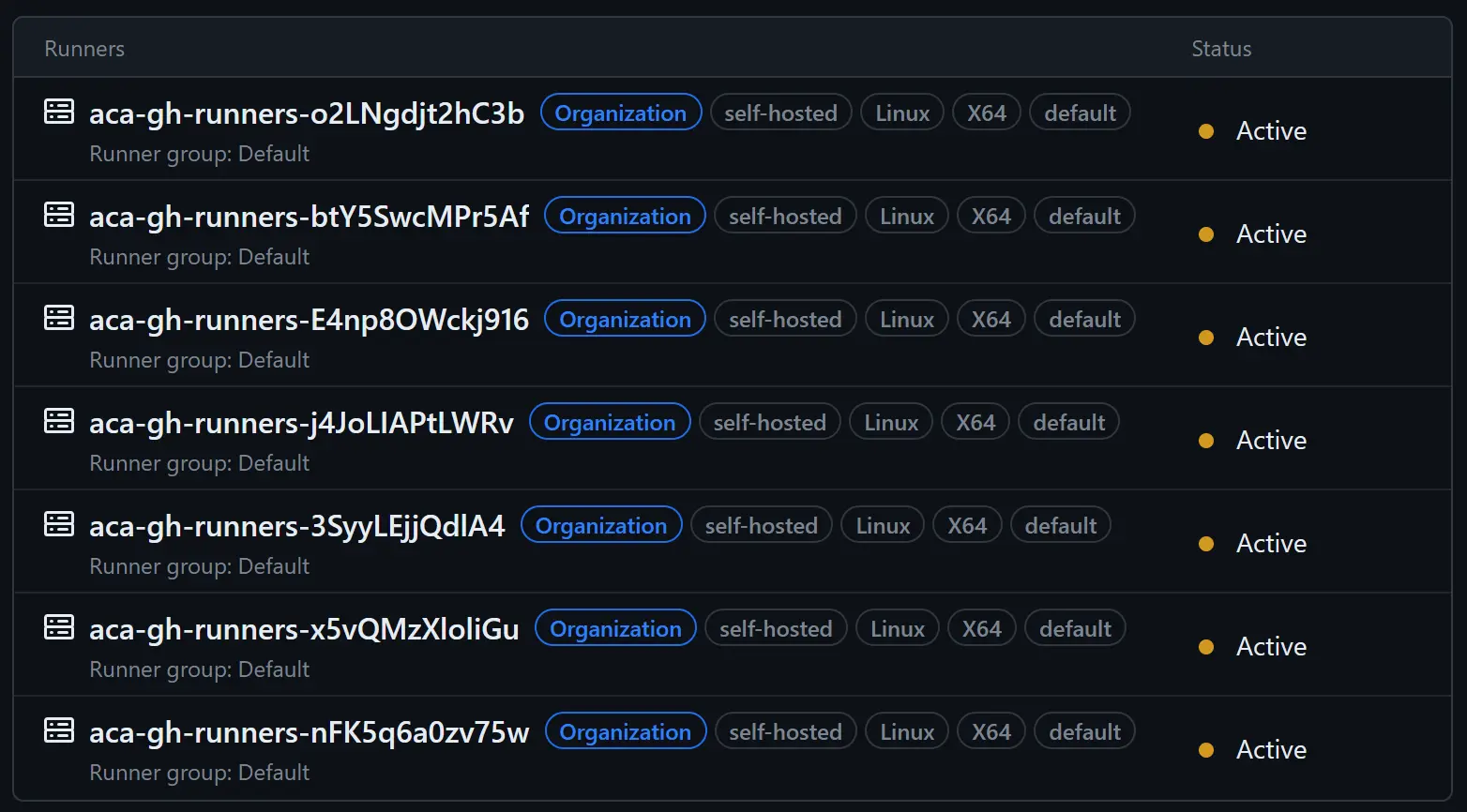 The jobs are being processed in parallel
The jobs are being processed in parallel
In the Azure portal, we can see the triggered jobs in the Execution history blade: 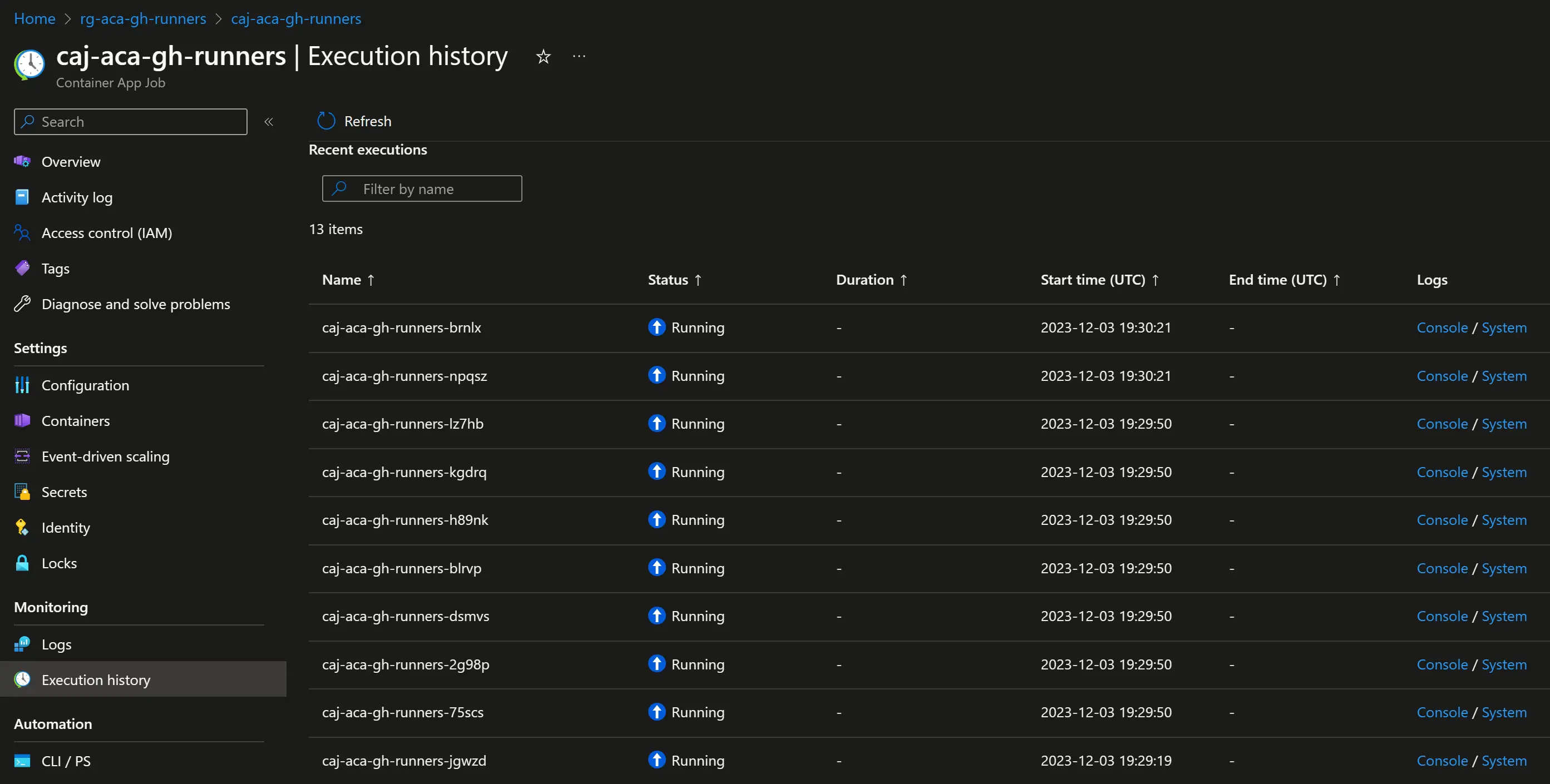 This is where we can monitor current and past runs From here we can also troubleshoot in the logs, sadly the Log stream blade is not available for jobs (yet ?) so we have to run queries in Log Analytics for that.
This is where we can monitor current and past runs From here we can also troubleshoot in the logs, sadly the Log stream blade is not available for jobs (yet ?) so we have to run queries in Log Analytics for that.
Once all the jobs have finished, everything is marked as ✅ Succeded (or ❌ Failed) in the Azure portal, and no runner appears anymore in the GitHub UI as the KEDA scaler have scaled them to 0.
I have kept the default scaling parameters (0 to 10 instances). This can be changed and even combined with other rules like a CRON one if you want to keep at least one instance ready during the day for faster startup and usage optimization
One last word about GitHub tokens
This section describes a problem I had when initially publishing this article. It has been since resolved and the solution described in a follow-up post.
At the time of publishing this post, to be honest I still have an issue regarding authentication against the GitHub REST API: after a few hours the generated token expires, the scaler gets 401 errors and the runners don’t register.
To workaround this I re-deploy the runners to get a fresh GitHub installation token (I could also use a schedule).
I have tried several ways to fix this, without success for now. There is an optional feature in GitHub Apps regarding expiration that I have disabled, but it didn’t make any change (it might target user tokens only, I am using installation tokens).
I guess another way will be to pass the GitHub App private key to the container and let it generate its tokens. The image I’m using supports that but not the scaler yet so I still need to generate tokens.
And of course I won’t do that without putting the key in an Azure Key Vault. This could be an opportunity to automate this part, maybe in another post 😏
If you have any lead for me please let me know in the comments 🤗
Wrapping-up
This was initially the end of the series about GitHub self-hosted runners in Azure Container Apps, but I have added a third post in the meantime. This second post is longer that I have first imagined as I decided to switch to jobs half-way through the writing process.
Anyway, I hope this series is useful I you want to test this solution. The goal was to provide enough information to start, avoid some mistakes I made along the way, and let you adapt it to your organization/environment.
Thanks again for reading, don’t hesitate to reach out in the comments below if you have any questions or anything to share on this topic !